
Annotation Jobs on GATE Cloud
1. Overview
GATE Cloud annotation jobs provide a way to quickly process large numbers of documents using a GATE application, with the results exported to files in GATE XML, XCES or JSON format and/or sent to a Mimir server for indexing. Annotation jobs are optimized for the processing of large batches of documents (tens of thousands or more) rather than processing single documents on the fly. For small numbers of documents, consider the on-line REST API instead.
To submit an annotation job you first choose which GATE application you want to run. GATE Cloud provides some standard options, or you can provide your own application. You then upload the documents you wish to process packaged up into ZIP or (optionally compressed) TAR archives, ARC or WARC files (as produced by the Heritrix web crawler), or (optionally compressed) streams of concatenated JSON objects (a common format for social media data such as Twitter or DataSift), and decide which annotations you would like returned as output, and in what format.
When the job is started, GATE Cloud takes the document archives you provided and divides them up into manageable-sized batches of up to 15,000 documents. Each batch is then processed using the open-source GCP tool and the generated output files are packaged up and made available for you to download from the GATE Cloud site when the job has completed.
2. Pricing
GATE Cloud annotation jobs run on a public cloud, which charges us per hour for the processing time we consume. As GATE Cloud allows you to run your own GATE application, and different GATE applications can process radically different numbers of documents in a given amount of time (depending on the complexity of the application) we cannot easily adopt the "£x per thousand documents" pricing structure used by other similar services. Instead, GATE Cloud passes on to you, the user, the per-hour charges we pay to the cloud provider plus a small mark-up to cover our own costs.
For a given annotation job, we add up the total amount of compute time taken to process all the individual batches of documents that make up your job (counted in seconds), round this number up to the next full hour and multiply this by the hourly price for the particular job type to get the total cost of the job. For example, if your annotation job was priced at £1 per hour and split into three batches that each took 56 minutes of compute time then the total cost of the job would be £3 (178 minutes of compute time, rounded up to 3 hours). However, if each batch took 62 minutes to process then the total cost would be £4 (184 minutes, rounded up to 4 hours).
While the job is running, we apply charges to your account whenever a job has consumed ten CPU hours since the last charge (which may take considerably less than ten real hours as several batches will typically execute in parallel). If your GATE Cloud account runs out of funds at any time, all your currently-executing annotation jobs will be suspended. You will be able to resume the suspended jobs once you have topped up your account to clear the negative balance. Note that it is not possible to download the result files from completed jobs if your GATE Cloud account is overdrawn.
3. Defining an annotation job
Straightforward annotation jobs can be configured and run directly from your GATE Cloud dashboard. Find the pipeline you want to run in the GATE Cloud shop, or select the custom annotation job option if you want to upload your own pipeline, and "reserve" a job. Confirm your order, and you will see a link to the job configuration tool.

The web-based configuration tool lets you rename the job, and select the data you want to process and the output format (or formats) you want the job to produce.
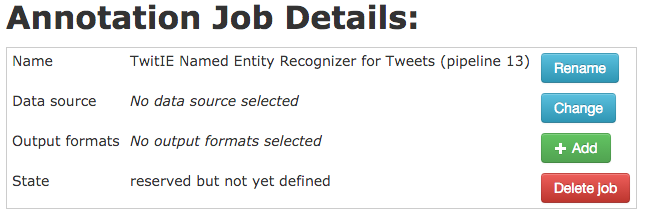
A job takes its input from a data bundle, which is a collection of data files, all of the same kind (ZIP files, WARC files, etc.). You can create a data bundle by uploading files directly from your local machine, or you can use a bundle that was created automatically as the output of another annotation job.
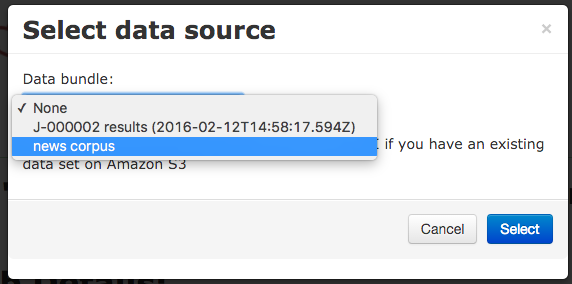
You also need to configure an output format for the job. Several file-based output formats are available, including GATE XML format, or you can choose to save the results as JSON or send them to Mímir for indexing.
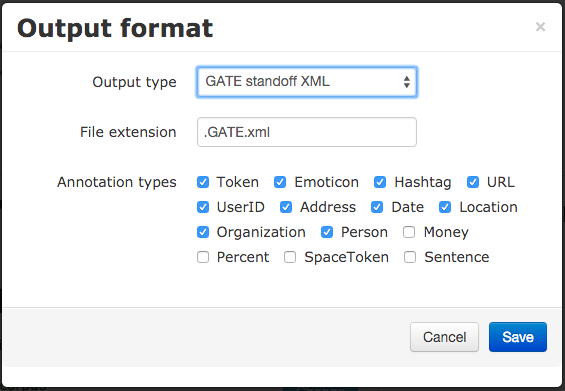
For pre-packaged pipelines, the platform knows what annotations the pipeline can produce and offers these options as checkboxes. For a custom job you need to specify the types you want explicitly, or leave the filters blank to save all annotations from all annotation sets. To index your annotations in Mímir, you must specify the URL of your index (which can be on a GATE Cloud Mímir server or one of your own that is accessible from the Internet).
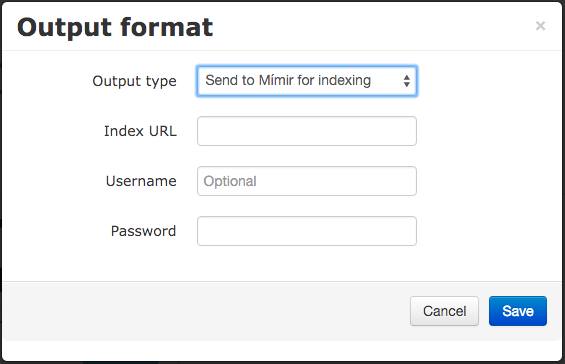
You can add several different output formats to a job, but be aware that if your job produces more than one kind of output then the resulting bundle will not be usable as the input to other jobs.
Once the job is fully configured you can use the control buttons to set it running. When the job completes, its output data will go into a new data bundle from which you can download it, or feed it to another job for further processing. You can also download the job execution reports and log files which may help you debug any problems.
When you have finished with a job you can delete it, or reset it and run it again, but note that this does not delete the result data bundle. This must be deleted separately, and you will continue to incur data storage charges for the bundle until you delete it.
The dashboard UI offers access to the most common types of job configuration, but the GATE Cloud platform also supports more complex modes. For example if you have your own data already stored in Amazon S3 you can create a data bundle pointing to that directly rather than having to download the data and re-upload it to GATE Cloud. To take advantage of the full range of options, you need to use the job management REST API.
4. Job execution in detail
Each job on GATE Cloud consists of a number of individual tasks.
- First a single "split" task which takes the initial document archives that
were provided when the job was configured and splits them into manageable
batches for processing.
- ARC files are not currently split - each complete ARC file will be processed as a single processing task.
- ZIP files that are smaller than 50MB will not be split, and will be processed as a single processing task.
- ZIP files larger than 50MB, and all TAR files, will be split into chunks of maximum size 50MB (compressed size) or 15,000 documents, whichever is the smaller. Each chunk will be processed as a separate processing task.
- JSON files larger than 50MB will be split similarly.
- One or more processing tasks, as determined by the split task described
above.
- Each processing task will run the GATE application over the documents from its input chunk as defined by the input specification, and save any output files in ZIP archives or JSON streams (depending how the job is configured) of no more than 100MB, which will be available to download once the job is complete.
- A final "join" task to collate the execution logs from the processing tasks and produce an overall summary report.
Note that because ZIP and TAR input files may be split into chunks, it is important that each input document in the archive should be self-contained, for example XML files should not refer to a DTD stored elsewhere in the ZIP file. If your documents do have external dependencies such as DTDs then you have two choices, you can either (a) use GATE Developer to load your original documents and re-save them as GATE XML format (which is self contained), or (b) use a custom job and include the additional files in your application ZIP, and refer to them using absolute paths.